How to Open and Read a Csv File in Python
This article will cover a tutorial on handling "csv" files using Python. The term "csv" stands for "comma separated values" where each row or line contains text based values delimited by commas. In some cases, "semicolon" is also used instead of "comma" to separate values. However, this doesn't make much difference to file format rules and the logic to handle both types of separators remains the same.
CSV file format is most commonly used for maintaining databases and spreadsheets. The first line in a CSV file is most commonly used to define column fields while any other remaining lines are considered rows. This structure allows users to present tabular data using CSV files. CSV files can be edited in any text editor. However, applications like LibreOffice Calc provide advanced editing tools, sort, and filter functions.
Reading Data from CSV Files Using Python
The CSV module in Python allows you to read, write and manipulate any data stored in CSV files. In order to read a CSV file, you will need to use the "reader" method from Python's "csv" module that is included in Python's standard library.
Consider that you have a CSV file containing following data:
Mango,Banana,Apple,Orange
50,70,30,90
The first row of the file defines each column category, name of fruits in this case. The second line stores values under each column (stock-in-hand). All these values are delimited by a comma. If you were to open this file in a spreadsheet application like LibreOffice Calc, it would look like this:
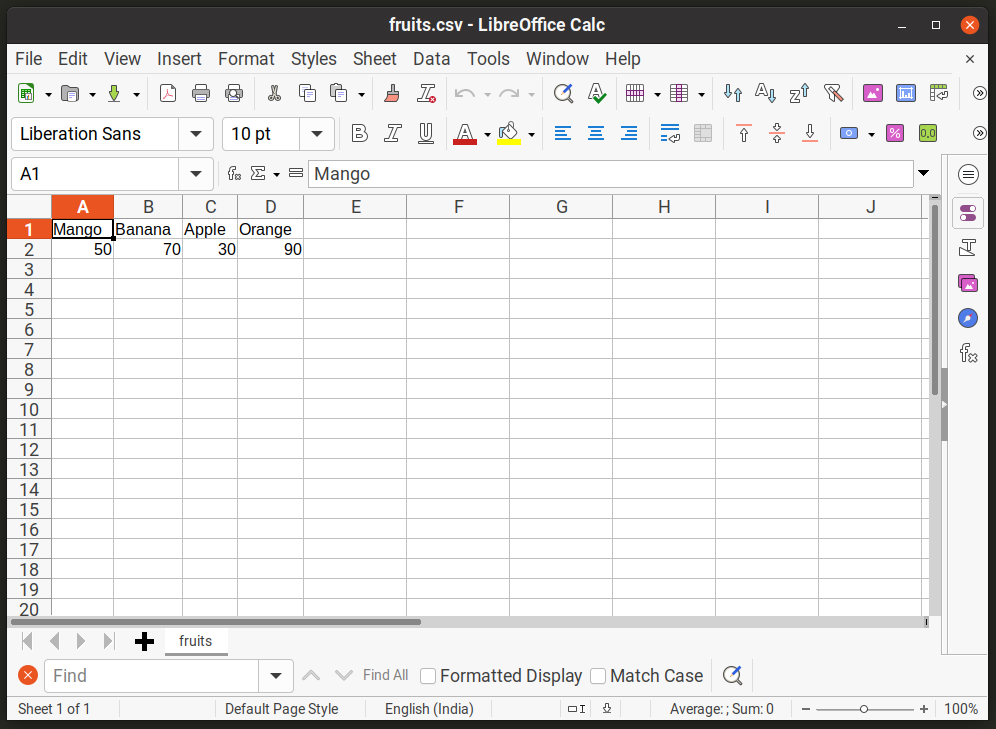
Now to read values from "fruits.csv" file using the Python's "csv" module, you will need to use the "reader" method in the following format:
import csv
with open ( "fruits.csv" ) as file:
data_reader = csv.reader ( file )
for line in data_reader:
print (line)
The first line in the above sample imports the "csv" module. Next, "with open" statement is used to safely open a file stored on your hard drive ("fruits.csv" in this case). A new "data_reader" object is created by calling the "reader" method from the "csv" module. This "reader" method takes a filename as a mandatory argument, so the reference to "fruits.csv" is passed to it. Next, a "for" loop statement is run to print each line from the "fruits.csv" file. After running the code sample mentioned above, you should get the following output:
If you want to assign line numbers to output, you can use the "enumerate" function that assigns a number to each item in an iterable (starting from 0 unless changed).
import csv
with open ( "fruits.csv" ) as file:
data_reader = csv.reader ( file )
for index, line in enumerate (data_reader):
print (index, line)
The "index" variable keeps the count for each element. After running the code sample mentioned above, you should get the following output:
0 ['Mango', 'Banana', 'Apple', 'Orange']
1 ['50', '70', '30', '90']
Since the first line in a "csv" file typically contains column headings, you can use "enumerate" function to extract these headings:
import csv
with open ( "fruits.csv" ) as file:
data_reader = csv.reader ( file )
for index, line in enumerate (data_reader):
if index == 0:
headings = line
print (headings)
The "if" block in the statement above checks if the index is equal to zero (first line in "fruits.csv" file). If yes, then the value of the "line" variable is assigned to a new "headings" variable. After, running the code sample above, you should get the following output:
['Mango', 'Banana', 'Apple', 'Orange']
Note that you can use your own delimiter when calling "csv.reader" method by using an optional "delimiter" argument in the following format:
import csv
with open ( "fruits.csv" ) as file:
data_reader = csv.reader ( file , delimiter= ";" )
for line in data_reader:
print (line)
Since in a csv file, each column is associated with values in a row, you may want to create a Python "dictionary" object when reading data from a "csv" file. To do so, you need to use "DictReader" method, as shown in the code below:
import csv
with open ( "fruits.csv" ) as file:
data_reader = csv.DictReader ( file )
for line in data_reader:
print (line)
After running the code sample mentioned above, you should get the following output:
{'Mango': '50', 'Banana': '70', 'Apple': '30', 'Orange': '90'}
So now you have a dictionary object that associates individual columns with their corresponding values in the rows. This works fine if you have only one row. Let's assume that the "fruits.csv" file now includes an additional row that specifies how many days it will take for the stock of fruit to perish.
Mango,Banana,Apple,Orange
50,70,30,90
3,1,6,4
When you have multiple rows, running the same code sample above will produce different output.
{'Mango': '50', 'Banana': '70', 'Apple': '30', 'Orange': '90'}
{'Mango': '3', 'Banana': '1', 'Apple': '6', 'Orange': '4'}
This may not be ideal as you may want to map all values pertaining to one column to one key-value pair in a Python dictionary. Try this code sample instead:
import csv
with open ( "fruits.csv" ) as file:
data_reader = csv.DictReader ( file )
data_dict = { }
for line in data_reader:
for key, value in line.items ( ):
data_dict.setdefault (key, [ ] )
data_dict[key].append (value)
print (data_dict)
After running the code sample mentioned above, you should get the following output:
{'Mango': ['50', '3'], 'Banana': ['70', '1'], 'Apple': ['30', '6'], 'Orange': ['90', '4']}
A "for" loop is used on each element of the "DictReader" object to loop over key-value pairs. A new Python dictionary variable "data_dict" is defined before that. It will store final data mappings. Under the second "for" loop block, Python dictionary's "setdefault" method is used. This method assigns a value to a dictionary key. If the key-value pair doesn't exist, a new one is created from the specified arguments. So in this case, a new empty list will be assigned to a key if it doesn't already exist. Lastly, "value" is appended to its corresponding key in the final "data_dict" object.
Writing Data to a CSV File
To write data to a "csv" file, you will need to use the "writer" method from the "csv" module. The example below will append a new row to the existing "fruits.csv" file.
import csv
with open ( "fruits.csv" , "a" ) as file:
data_writer = csv.writer ( file )
data_writer.writerow ( [ 3 , 1 , 6 , 4 ] )
The first statement opens the file in "append" mode, denoted by the argument "a". Next the "writer" method is called and the reference to "fruits.csv" file is passed to it as an argument. The "writerow" method writes or adds a new row to the file.
If you want to convert Python dictionary to a "csv" file structure and save the output in a "csv" file, try this code:
import csv
with open ( "fruits.csv" , "w" ) as file:
headings = [ "Mango" , "Banana" , "Apple" , "Orange" ]
data_writer = csv.DictWriter ( file , fieldnames=headings)
data_writer.writeheader ( )
data_writer.writerow ( { "Mango": 50 , "Banana": 70 , "Apple": 30 , "Orange": 90 } )
data_writer.writerow ( { "Mango": 3 , "Banana": 1 , "Apple": 6 , "Orange": 4 } )
After opening an empty "fruits.csv" file using a "with open" statement, a new variable "headings" is defined that contains column headings. A new object "data_writer" is created by calling the "DictWriter" method and passing it reference to the "fruits.csv" file and a "fieldnames" argument. In the next line, column headings are written to the file using the "writeheader" method. The last two statements add new rows to their corresponding headings created in the previous step.
Conclusion
CSV files provide a neat way to write data in tabular format. Python's built-in "csv" module makes it easy to handle data available in "csv" files and implement further logic on it.
About the author
![]()
I am a freelancer software developer and content writer who loves Linux, open source software and the free software community.
How to Open and Read a Csv File in Python
Source: https://linuxhint.com/handle-csv-files-python/